B.4 Execução de Instruções
Um conjunto de instruções é um conjunto de bits devidamente codificados que indica ao computador que sequência de micro-operações ele deve realizar. Elas podem ser classificadas, dentre outras formas, como (WEBER, 2004):
- Instruções de transferência de dados
- Instruções aritméticas e lógicas
- Instruções de teste e desvio
O conjunto de instruções envolve o conjunto de todas as instruções que um computador reconhece e pode executar. Todo programa é formado por uma sequência finita de instruções de um determinado conjunto de instruções. A maioria das instruções que formam um programa realiza operações que envolvem operandos (dados), que podem estar em qualquer posição de memória ou em algum registrador.
Para que a UC consiga localizar o operando é necessário que o endereço dele seja indicado junto com a instrução. Nas instruções que envolvem a operação de desvio é necessário indicar para qual posição ou endereço de programa será realizado o desvio.
B.4.1 Sequência de Funcionamento
A sequência para a realização de uma instrução pelo processador é conhecida como ciclo de “busca – decodificação – execução” de instruções.
Uma instrução é buscada por vez para ser executada, de acordo com os seguintes passos:
- Busca da próxima instrução na memória;
- Decodificação da instrução;
- Dados que servirão como operandos são buscados na memória, se for necessário;
- Cálculo do endereço da próxima instrução;
- Execução da instrução;
- Armazenamento do resultado.
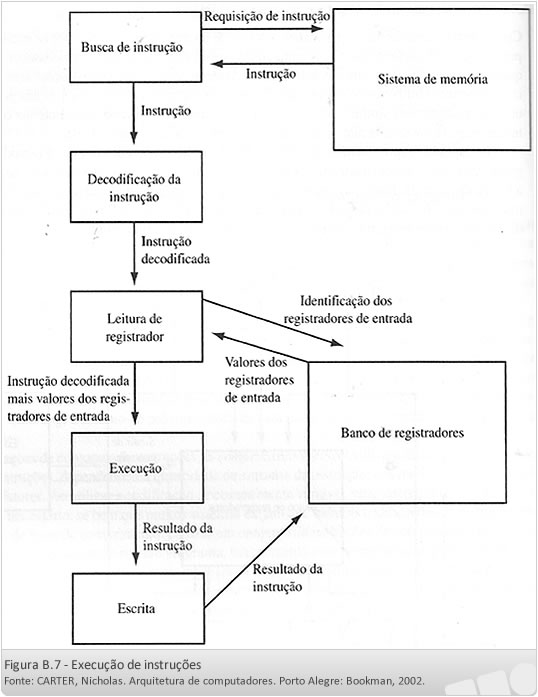
No ciclo de instrução, as seguintes ações são executadas:
- Transferência do conteúdo do endereço de memória apontado pelo contador de programa (PC) como sendo da próxima instrução a ser executada para o RI.
- Atualizar o valor de PC para indicar o endereço da próxima instrução a ser executada.
- O decodificador de instruções recebe o código da operação e o decodifica, enviando-o para a UC.
- A UC gera os sinais necessários para que a instrução possa ser executada.
A sequência do ciclo de instruções é executada para cada nova instrução a ser executada repetidamente e se constitui nas seguintes etapas (WEBER, 2004):
- Busca
- Copiar o PC para o registrador de endereços da memória (REM).
- Ler uma instrução da memória.
- Copiar o registrador de dados da memória (RDM) para o registrador de instruções (RI).
- Atualizar o contador de programa (PC).
- Decodificação
- Determina qual instrução deve ser executada.
- Execução
- Cálculo de endereço dos operandos (se houver).
- Busca dos operandos na memória (se houverem).
- Seleção da operação a ser realizada pela ULA.
- Carga de registradores.
- Escrita de operandos na memória.
- Atualização do PC (somente no caso das instruções serem desvios).
B.4.2 Pipelines
Nos computadores mais antigos as instruções eram executadas uma por uma, com o processador buscando uma instrução na memória, decodificando-a (determinar qual instrução era), lendo as entradas das instruções (no banco de registradores), executando os cálculos exigidos pela instrução e escrevendo os resultados de volta no banco de registradores. O problema desta abordagem é que o hardware necessário para executar cada um desses passos é diferente, de modo que a maior parte dele fica ocioso em um determinado momento, esperando que as outras partes do processador completem a sua parte de execução da instrução. (CARTER, 2002)
Com o objetivo de tornar ágil este processo, evita-se que elementos do processador fiquem parados, é utilizada a técnica de pipelining (pipe = tubo; line = sequência). Ela consiste em reduzir o tempo de execução de um conjunto de instruções, sendo que o tempo para executar uma instrução continua o mesmo, mas a quantidade de instruções executadas por um período de tempo aumenta. (CARTER, 2002)
| ||||
|


É uma técnica de implementação de CPU onde múltiplas instruções podem estar em execução ao mesmo tempo em estágios de processamento diferentes, sendo que cada um deles é responsável pela execução de uma parte da instrução e possui o seu próprio bloco de controle. Assim que um estágio completa sua tarefa com uma instrução, passa ela para o estágio seguinte e começa a tratar da próxima instrução. Sendo que várias instruções são executadas ao mesmo tempo, ocorre um acréscimo no desempenho do processador.
A execução de uma instrução, por exemplo, pode ser dividida em 5 estágios básicos:
- Busca de instruções (fetch)
- Decodificação de instruções (decode)
- Busca dos operandos e armazenamento em registradores (operand fetch)
- Execução de instruções (execute)
- Armazenamento do resultado em registradores (store)
Sem a utilização de pipeline a execução de uma instrução ocorreria da seguinte maneira:
Tempo |
EstÁgio1 |
EstÁgio2 |
EstÁgio3 |
EstÁgio4 |
EstÁgio5 |
1 |
processo1 |
Tempo |
EstÁgio1 |
EstÁgio2 |
EstÁgio3 |
EstÁgio4 |
EstÁgio5 |
1 |
|
||||
2 |
|
processo1 |
Tempo |
EstÁgio1 |
EstÁgio2 |
EstÁgio3 |
EstÁgio4 |
EstÁgio5 |
1 |
|
||||
2 |
|
|
|||
3 |
|
|
processo1 |
Tempo |
EstÁgio1 |
EstÁgio2 |
EstÁgio3 |
EstÁgio4 |
EstÁgio5 |
1 |
|
||||
2 |
|
|
|||
3 |
|
|
|
||
4 |
|
|
|
processo1 |
Tempo |
EstÁgio1 |
EstÁgio2 |
EstÁgio3 |
EstÁgio4 |
EstÁgio5 |
1 |
|
||||
2 |
|
|
|||
3 |
|
|
|
||
4 |
|
|
|
|
|
5 |
|
|
|
|
processo1 |
Tempo |
EstÁgio1 |
EstÁgio2 |
EstÁgio3 |
EstÁgio4 |
EstÁgio5 |
1 |
|
||||
2 |
|
|
|||
3 |
|
|
|
||
4 |
|
|
|
||
5 |
|
|
|
||
6 |
processo2 |
|
|
Dessa forma, quando um estágio estava ocupado executando sua função, os outros 4 estágios ficavam ociosos, assim como apenas um processo ocupa o processador, levando cinco unidades de tempo para executar e só então outro processo pode começar a ser processado.
Com a utilização de pipelines, o primeiro processo continua demorando cinco unidades de tempo para ser executado, mas logo a seguir, em cada unidade de tempo um novo processo é executado. Conforme segue:
Tempo |
EstÁgio1 |
EstÁgio2 |
EstÁgio3 |
EstÁgio4 |
EstÁgio5 |
1 |
processo1 |
Tempo |
EstÁgio1 |
EstÁgio2 |
EstÁgio3 |
EstÁgio4 |
EstÁgio5 |
1 |
processo1 |
||||
2 |
processo2 |
processo1 |
|
Tempo |
EstÁgio1 |
EstÁgio2 |
EstÁgio3 |
EstÁgio4 |
EstÁgio5 |
1 |
processo1 |
||||
2 |
processo2 |
processo1 |
|||
3 |
processo3 |
processo2 |
processo1 |
Tempo |
EstÁgio1 |
EstÁgio2 |
EstÁgio3 |
EstÁgio4 |
EstÁgio5 |
1 |
processo1 |
||||
2 |
processo2 |
processo1 |
|||
3 |
processo3 |
processo2 |
processo1 |
||
4 |
processo4 |
processo3 |
processo2 |
processo1 |
Tempo |
EstÁgio1 |
EstÁgio2 |
EstÁgio3 |
EstÁgio4 |
EstÁgio5 |
1 |
processo1 |
||||
2 |
processo2 |
processo1 |
|||
3 |
processo3 |
processo2 |
processo1 |
||
4 |
processo4 |
processo3 |
processo2 |
processo1 |
|
5 |
processo5 |
processo4 |
processo3 |
processo2 |
processo1 |
Tempo |
EstÁgio1 |
EstÁgio2 |
EstÁgio3 |
EstÁgio4 |
EstÁgio5 |
1 |
processo1 |
||||
2 |
processo2 |
processo1 |
|||
3 |
processo3 |
processo2 |
processo1 |
||
4 |
processo4 |
processo3 |
processo2 |
processo1 |
|
5 |
processo5 |
processo4 |
processo3 |
processo2 | processo1 |
6 |
processo6 |
processo5 |
processo4 |
processo3 |
processo2 |
Alguns estágios apresentam tempo de execução diferente dos outros, fazendo com que o tempo necessário para encher o pipeline e esvaziá-lo seja variável, com instruções ficando presas no pipeline, aguardando que as instruções que geram suas entradas sejam executadas. Também existe uma série de fatores que limitam a capacidade de um pipeline de executar instruções, como dependências entre instruções (leitura ou escrita de registradores que estão sendo utilizados por outras instruções), desvios (processador não sabe qual instrução deve buscar até que ocorra o desvio) e o tempo necessário para acessar a memória. (CARTER, 2002).
Devido à existência de fatores que podem comprometer o desempenho do uso de pipelines, existem técnicas que são utilizadas para amenizá-los:
- Pré-decodificação: o processador pode realizar a decodificação de instruções (paralelamente) antes do momento de elas serem executadas.
- Execução fora-de-sequência: o processador pode executar previamente um determinado número de instruções. Posteriormente, a ordem de execução é verificada e os resultados das operações são repassados na sua ordem correta.
- Previsão de desvio: caso exista uma instrução de desvio dentro do pipeline, ela pode ser calculada mais cedo (para determinar qual caminho será percorrido e descartar as instruções que não serão necessárias) no pipeline ou prever o destino de cada possibilidade de desvio, para que o processador possa procurar as instruções que serão necessárias anteriormente.
B.4.3 Medidas de Desempenho
Existem diversas formas de medir o desempenho de sistemas computacionais. Dentre elas podemos destacar:
- MIPS (Milhões de Instruções por Segundo): mede a execução de instruções, dividindo o número de instruções executadas de um programa pelo tempo necessário para executá-lo, não considerando que existem diferentes instruções, com tempos de execução diferentes.
- FLOPS (Operações de Ponto Flutuante por Segundo): mede basicamente o desempenho da ULA, analisando apenas quantas instruções complexas são executadas.
- Tempo de acesso: está relacionado à velocidade de cada componente e a do barramento que interliga o processador à memória, tratando o tempo gasto entre o instante em que foi realizada uma solicitação e o instante em que o sistema entregou a resposta.