Introdução
Na estrutura de computadores estudada até então, observamos os elementos existentes em uma arquitetura voltada para
Em um dado momento surgiu a necessidade de maior capacidade de processamento, surgindo então técnicas baseadas em concorrência. Nesse sentido, a utilização de diversos processadores em conjunto passou a ser empregada como uma forma de obter este ganho de desempenho e, com isso, surge o processamento paralelo, envolvendo técnicas relacionadas a esse tipo de implementação.
Com o avanço das técnicas de processamento paralelo foi aberto espaço para o surgimento de máquinas de grande capacidade de processamento, os chamados supercomputadores, amplamente utilizados em áreas de pesquisa que requerem grande processamento. No link a seguir é possível acompanhar uma reportagem referente ao supercomputador brasileiro netuno, onde podemos compreender melhor a utilidade do mesmo: Vídeo.
Arquiteturas paralelas
Tradicionalmente a arquitetura dos computadores encontra-se formada da seguinte forma:
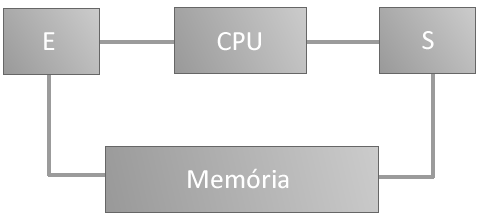
Nessa arquitetura existe uma unidade central de processamento e um sistema de entrada e de saída de dados que se relaciona com ela e diretamente com o sistema de memória (DMA). A memória oferece suporte a multiprogramação, armazenando vários programas a serem executados pela CPU, gerando um fluxo de instruções e um de dados.
Como forma de agilizar o processamento dos dados foram construídas arquiteturas com múltiplas CPU’s, sendo que existem várias formas de classificar essas arquiteturas, conforme veremos a seguir.
Classificação de Flynn
Para Flynn, uma forma de classificar arquiteturas paralelas é conforme elas se relacionam com o fluxo de instruções e com o fluxo de dados. Esses fluxos podem ser múltiplos ou simples e, com base nisso, propôs uma classificação em quatro classes:
| SD (Single Data) | MD (Multiple Data) | |
| SI(Single Instruction) | SISD Maquinas von Neumann convencionais |
SIMD |
| MI (Multiple Instruction) | MISD |
MIMD Multiprocessadores e multicomputadores (nCUBE, intel Paragon, Cray T3D) |
Tabela - Classificação de Flynn (Fonte: ROSE; NAVAUX. Arquiteturas Paralelas. Porto Alegre: Bookman, 2008)
Cada uma dessas quatro classes representa uma forma de se lidar com o processamento de instruções e de dados, conforme estudaremos a seguir.
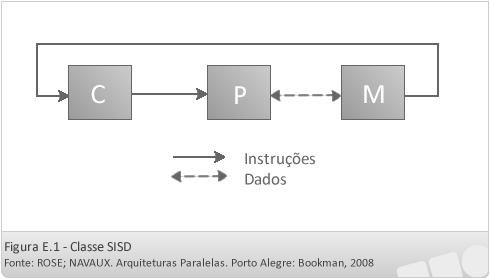
- SISD (Single Instruction Single Data)
Nessa classificação, um único fluxo de instruções trabalha sobre um único fluxo de dados. Nela, existe um único fluxo de instruções alimentando uma única unidade de controle (C) que coordena um único processador (P), que atua sobre um único fluxo de dados que é lido, processado e reescrito em uma única memória (M). Seu funcionamento é característico de máquinas compostas por um processador.
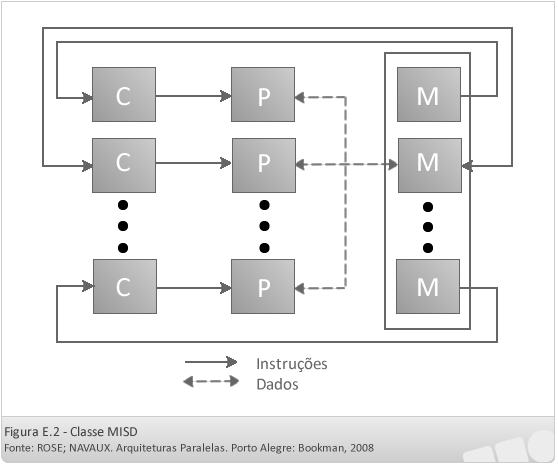
- MISD (Multiple Instruction Single Data)
Nessa classificação, existem múltiplos fluxos de instruções e um único fluxo de dados. Ela envolve múltiplos processadores (P) com sua própria unidade de controle (C) executando diferentes instruções sobre um único conjunto de dados. De forma prática, não é possível implementá-la, sendo uma classe apenas teórica.
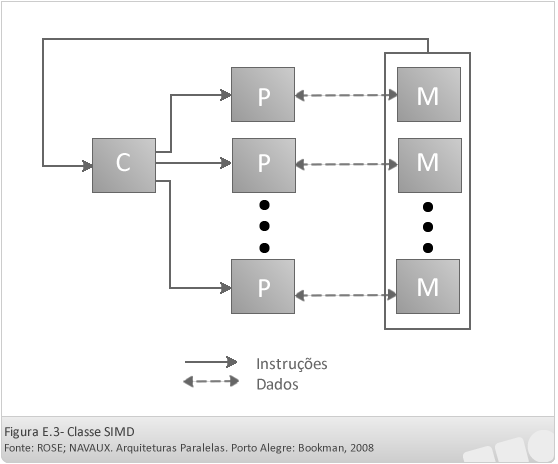
- SIMD (Single Instruction Multiple Data)
Nessa classificação, existe um único fluxo de instruções que é executado sobre múltiplos fluxos de dados. Nela, existe uma única unidade de controle (C) que comanda a execução de uma única instrução por diversos processadores (P). Cada processador executa uma parte da instrução de forma paralela (ao mesmo tempo), trabalhando sincronamente sobre diferentes fluxos de dados. Para que esse funcionamento seja possível é necessário que a memória (M) seja implementada em diversos módulos de memória, que possibilitem diversos acessos simultâneos a ela por parte dos diversos processadores.
- MIMD (Multiple Instruction Multiple Data)
Nessa classificação, existem múltiplos fluxos de instruções e múltiplos fluxos de dados. Nela, cada unidade de controle (C) recebe um fluxo instruções diferente e o encaminha para o processador (P) que está sob seu controle. Dessa forma, cada um dos processadores trabalha, assincronamente, sobre instruções diferentes, sendo que cada uma delas com seus próprios dados. O módulo de memória (M) deve ser implementado em diversos módulos de memória, que possibilitem diversos acessos simultâneos a ela por parte dos diversos processadores.
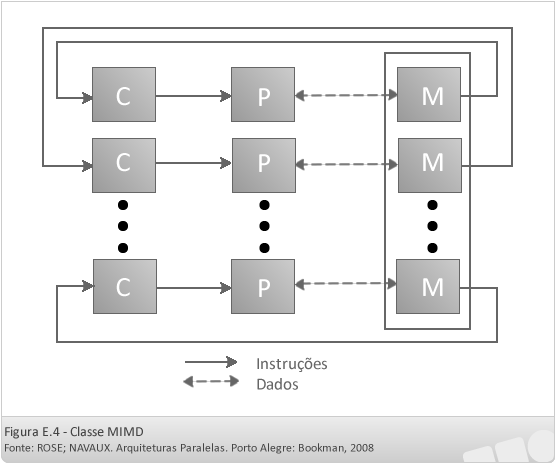
Com base ainda nessa classificação MIMD, ela pode se subdividir quanto a forma como a memória é acessada. Quando a memória é acessada de forma compartilhada pelos diversos processadores, a máquina é conhecida como de multiprocessadores, ou seja, uma única máquina composta por vários processadores que compartilham o mesmo espaço de endereçamento. Quando a memória não é compartilhada entre os processadores, a máquina é conhecida como de multicomputadores, sendo que, existem diferentes máquinas, com cada uma delas possuindo sua própria memória e processadores, que devem se comunicar através de trocas de mensagens para manter o correto funcionamento de todo o sistema computacional.
Classificação segundo o compartilhamento de memória
Seguindo a classificação apresentada no MIMD, de onde temos os multiprocessadores e os multicomputadores, a forma como a memória é acessada constituí-se em um elemento importante, pois determinará como que ela será compartilhada entre os diversos processadores.
Esse compartilhamento segue a seguinte classificação:
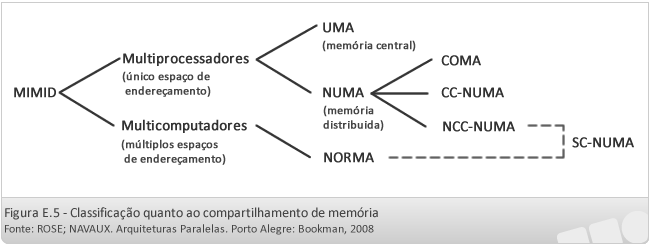
Quanto às máquinas de multiprocessadores pode-se trabalhar com as seguintes formas de se acessar a memória:
- Máquina UMA (Uniform memory access)
Nesse tipo de máquina a memória é centralizada, ficando a uma distância igual de todos os processadores que compõem o sistema, garantindo desta forma que o acesso a ela leve o mesmo tempo para cada um deles. Como ela é centralizada, é utilizado apenas um barramento ligando-a a todos os barramentos, sendo assim, só pode ser realizado um acesso por vez à memória (quando ela está sendo acessada por um processador todos os outros devem aguardar sua vez).
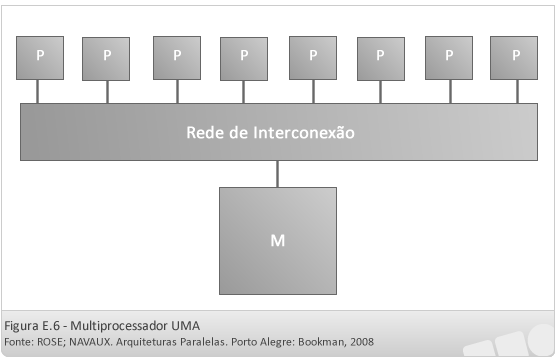
Um fator que deve ser considerado em sua implementação é o de que cada processador possui sua própria cache, sendo que a informação que está na cache de um determinado processador pode ser alterada na cache de outro e armazenada novamente na memória, o que pode resultar em que o conteúdo da cache de um processador acabe ficando desatualizada. A possibilidade de isto ocorrer torna importante a existência de uma coerência entre as caches de cada processador, para que estejam sempre atualizadas. Esse problema costuma ser resolvido via hardware específico.
- Máquina NUMA (non-uniform memory access)
Nesse tipo de máquina a memória é distribuída, sendo composta por vários módulos, cada um deles pertencendo a um processador específico. Nessa organização cada processador leva um tempo menor para acessar sua própria memória e tempos mais demorados para acessar a memória pertencente a outros processadores, resultando em acessos não-uniformes à memória, pois dependerá de qual memória deverá ser acessada, (se a do próprio processador ou de algum outro) o que acarretará em tempos diferentes de acesso.
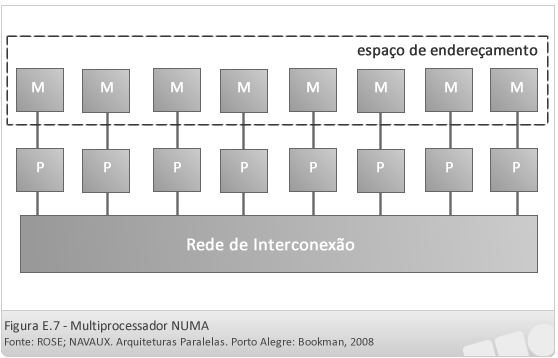
De acordo com a forma como é trabalhada a questão da coerência de cache a máquina NUMA pode ser subdividida em:
- NCC-NUMA (non-cache-coherent non-uniform memory access): onde não existe preocupação com a coerência de cache em hardware;
- CC-NUMA (cache-coherent non-uniform memory access): existe a garantia de coerência de cache através de hardware;
- SC-NUMA (software-coherent non-uniform memory access): nela existe a garantia de coerência de cache através de software.
- Máquina COMA (cache-only memory architecture)
Nesse tipo de máquina as memórias locais são formadas na verdade por memórias cache de maior capacidade que as convencionais, possuindo hardware de replicação que permite a transferência de conteúdo entre as caches.
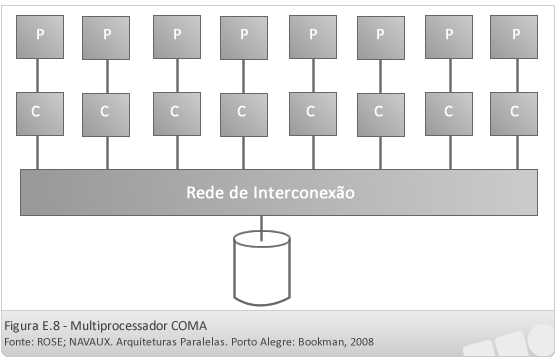
O outro tipo de máquinas existente são as compostas por multicomputadores. Essas máquinas, quanto ao acesso à memória, podem ser classificadas como:
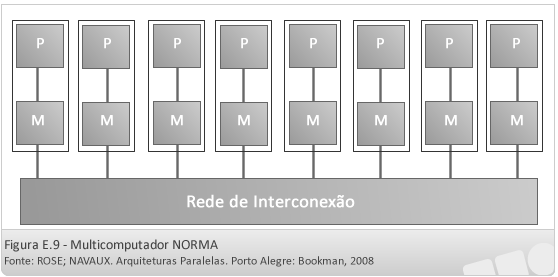
- Máquina NORMA (non-remote memory access)
Nesse caso, como cada máquina possui uma arquitetura completa, cada processador somente acessa a área de endereçamento local de sua própria máquina.